hadoop
2023 年 3 月 8 日
HADOOP_HDFS搭建
学习搭建hadoop_hdfs
Hadoop-HDFS 搭建学习(单机、伪分布式以及高可用模式)
2023-03-08 16:57
在搭建之前,可以先看我博客当中的centos stream9的搭建步骤,完成集群的基础配置,设置需要四个节点。
一、搭建伪分布式hadoop(所有角色设在一个节点)
1. 在集群中,首先创建新的文件目录
mkdir /opt/bigdata
创建目录如下
2. 从sftp上传hadoop jar包,并解压到bigdata 目录下
tar -xf hadoop-2.6.5.tar.gz
解压后如下图
3.修改环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile4.配置hadoop的角色
4.1 必须给hadoop配置javahome要不ssh过去找不到cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/java/default
修改配置环境
4.2 给出NN角色在哪里启动以及datanode和 secondarynode 地址vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
配置hdfs 副本数为1.。。。
vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
给出存放数据的地址,hdfs映射本地的路径,是一个文件管理系统
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>以上的配置信息可参考官网 单节点配置hadoop信息
4.3 配置 DN 这个角色在哪里启动 vim slaves
node015.初始化并启动
hdfs namenode -format
创建目录
并初始化一个空的fsimage
start-dfs.sh
第一次:datanode和secondary角色会初始化创建自己的数据目录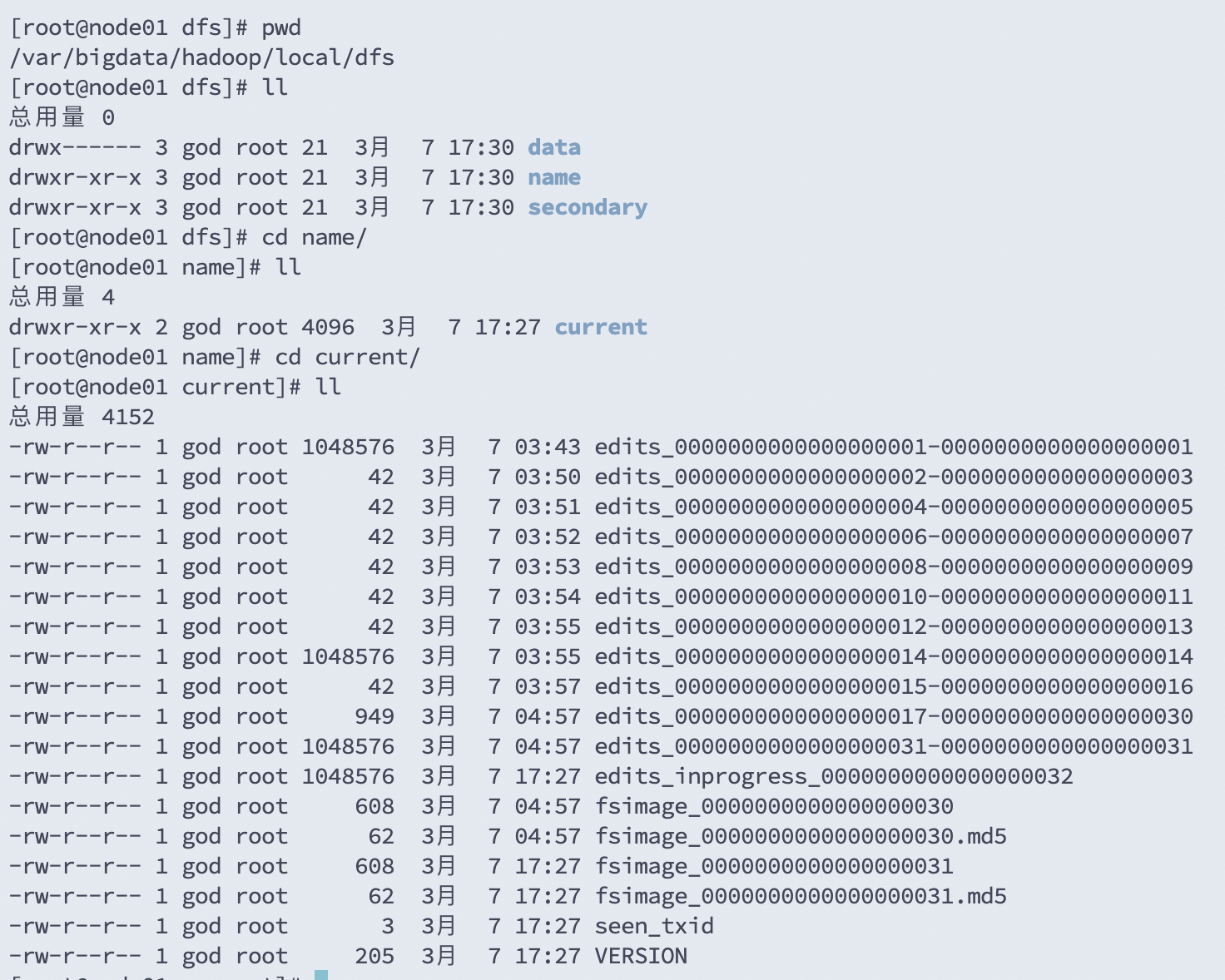
去目录下查看
6.更改电脑 hosts 文件,配置与服务器相同的ip地址与hostname做对应
vim /etc/hosts
node01 10.211.55.101
node02 10.211.55.102
node03 10.211.55.103
node04 10.211.55.1047.打开 http://node01:50070
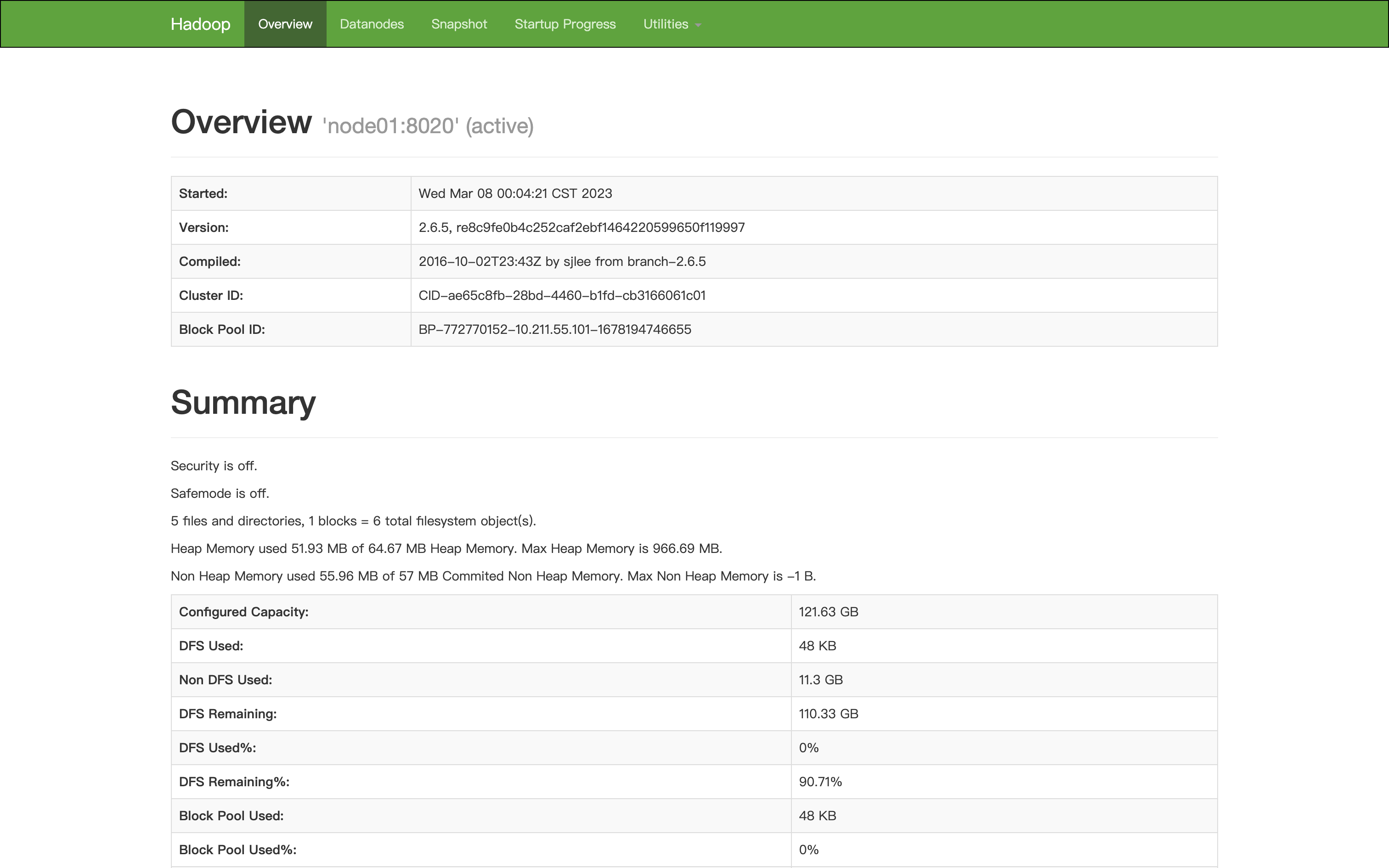
如下界面则为成功
8.简单使用
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root二、搭建完全分布式集群hadoop(全部角色在一个节点)
1.角色重新规划
stop-dfs.sh1.1为什么要配置免密?
启动start-dfs.sh:在哪里启动,那台就要对别人公开自己的公钥
1.2 配置部署 node01:
cd $HADOOP/etc/hadoop
vim core-site.xml 不需要改
vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/full/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/full/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/full/dfs/secondary</value>
</property>1.3配置datanode启动节点 vi slaves
node02
node03
node041.4 将数据分发至其余节点 cd /opt
scp -r ./bigdata/ node02:`pwd`
scp -r ./bigdata/ node03:`pwd`
scp -r ./bigdata/ node04:`pwd`1.5 格式化启动 hdfs namenode -format
start-dfs.sh三、搭建高可用模式 hadoop(HA 模式)
1.HA模式下:有一个问题,你的NN是2台?在某一时刻,谁是Active呢?client是只能连接Active。修改配置文件并给每一套都分发(scp …)
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
hdfs-site.xml
#以下是 一对多,逻辑到物理节点的映射
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
#以下是JN在哪里启动,数据存那个磁盘
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property>
#HA角色切换的代理类和实现方法,我们用的ssh免密
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
#开启自动化: 启动zkfc
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
core-site.xml修改
2. 流程。
2.1 基础设施
2.1.1 ssh 免密
1)启动start-dfs.sh脚本的机器需要将公钥分发给别的节点
2)在HA模式下,每一个NN身边会启动ZKFC,ZKFC会用免密的方式控制自己和其他NN节点的NN状态
2.1.2 应用搭建
1) HA 依赖 ZK 搭建ZK集群
2)修改hadoop的配置文件,并集群同步
2.1.3 初始化启动
1)先启动JN hadoop-daemon.sh start journalnode
2)选择一个NN 做格式化:hdfs namenode -format<只有第一次搭建做,以后不用做>
3)启动这个格式化的NN,以备另外一台同步 hadoop-daemon.sh start namenode
4)在另外一台机器中: hdfs namenode -bootstrapStandby
5)格式化zk: hdfs zkfc -formatZK <只有第一次搭建做,以后不用做>
6) start-dfs.sh3. 实操。
3.1 停止之前的集群
3.2 免密:node01,node02 node02:
cd ~/.ssh
ssh-keygen -t dsa -P '' -f ./id_dsa
cat id_dsa.pub >> authorized_keys
scp ./id_dsa.pub node01:`pwd`/node02.pub
node01:
cd ~/.ssh
cat node02.pub >> authorized_keys3.3 zookeeper 集群搭建,需要jdk,部署在2,3,4 node02:
tar xf zook....tar.gz
mv zoo... /opt/bigdata
cd /opt/bigdata/zoo....
cd conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
datadir=/var/bigdata/hadoop/zk
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
mkdir /var/bigdata/hadoop/zk
echo 1 > /var/bigdata/hadoop/zk/myid
vi /etc/profile
export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
. /etc/profile
cd /opt/bigdata
scp -r ./zookeeper-3.4.6 node03:`pwd`
scp -r ./zookeeper-3.4.6 node04:`pwd`
node03:
mkdir /var/bigdata/hadoop/zk
echo 2 > /var/bigdata/hadoop/zk/myid
*环境变量
. /etc/profile
node04:
mkdir /var/bigdata/hadoop/zk
echo 3 > /var/bigdata/hadoop/zk/myid
*环境变量
. /etc/profile
node02~node04:
zkServer.sh start3.4 初始化
1)先启动JN hadoop-daemon.sh start journalnode
2)选择一个NN 做格式化:hdfs namenode -format<只有第一次搭建做,以后不用做>
3)启动这个格式化的NN ,以备另外一台同步 hadoop-daemon.sh start namenode
4)在另外一台机器中: hdfs namenode -bootstrapStandby
5)格式化zk: hdfs zkfc -formatZK <只有第一次搭建做,以后不用做>
1) start-dfs.sh
3.5使用验证:
1)去看jn的日志和目录变化:
2)node04
zkCli.sh
ls /
启动之后可以看到锁:
get /hadoop- ha/mycluster/ActiveStandbyElectorLock
3)杀死namenode 杀死zkfc
kill -9 xxx
a)杀死active NN
b)杀死active NN身边的zkfc
c)shutdown activeNN 主机的网卡 : ifconfig eth0 down
2节点一直阻塞降级
如果恢复1上的网卡 ifconfig eth0 up
最终 2编程active
node01
四、用户 HDFS权限
1.理论
hdfs是一个文件系统
类unix、linux
有用户概念
hdfs没有相关命令和接口去创建用户
信任客户端 <- 默认情况使用的 操作系统提供的用户
扩展 kerberos LDAP 继承第三方用户认证系统
有超级用户的概念
linux系统中超级用户:root
hdfs系统中超级用户: 是namenode进程的启动用户
有权限概念
hdfs的权限是自己控制的 来自于hdfs的超级用户2.实操
切换我们用root搭建的HDFS 用god这个用户来启动 node01~node04:
*)stop-dfs.sh
1)添加用户:root
useradd god
passwd god
2)讲资源与用户绑定(a,安装部署程序;b,数据存放的目录)
chown -R god src
chown -R god /opt/bigdata/hadoop-2.6.5
chown -R god /var/bigdata/hadoop
3)切换到god去启动 start-dfs.sh < 需要免密
给god做免密
*我们是HA模式:免密的2中场景都要做的
ssh localhost >> 为了拿到.ssh
node01~node02:
cd /home/god/.ssh
ssh-keygen -t rsa -P '' -f ./id_rsa
node01:
ssh-copy-id -i id_rsa node01
ssh-copy-id -i id_rsa node02
ssh-copy-id -i id_rsa node03
ssh-copy-id -i id_rsa node04
node02
cd /home/god/.ssh
ssh-copy-id -i id_rsa node01
ssh-copy-id -i id_rsa node02
4)hdfs-site.xml
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/god/.ssh/id_rsa</value>
</property>
分发给node02~04
5)god : start-dfs.sh3.用户权限认证
node01:
su god
hdfs dfs -mkdir /temp
hdfs dfs -chown god:ooxx /temp
hdfs dfs -chmod 770 /temp
node04:
root:
useradd good
groupadd ooxx
usermod -a -G ooxx good
id good
su good
hdfs dfs -mkdir /temp/abc <失败
hdfs groups
good: <因为hdfs已经启动了,不知道你操作系统又偷偷摸摸创建了用户和组
*node01:
root:
useradd good
groupadd ooxx
usermod -a -G ooxx good
su god
hdfs dfsadmin -refreshUserToGroupsMappings
node04:
good:
hdfs groups
good : good ooxx
结论:默认hdfs依赖操作系统上的用户和组五、IDEA 实操

POM文件
服务器上传两个配置文件,data.txt是自己写的。

java文件
版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
作者: 发表日期:2023 年 3 月 8 日